Graph-based exploration
Discover related documents
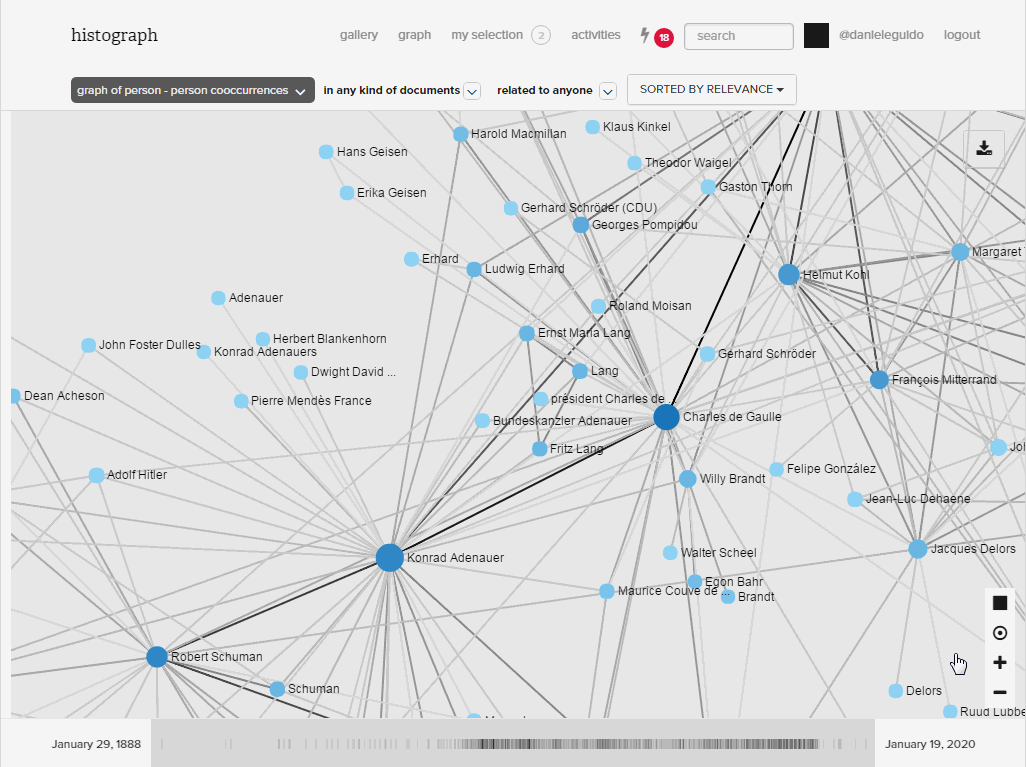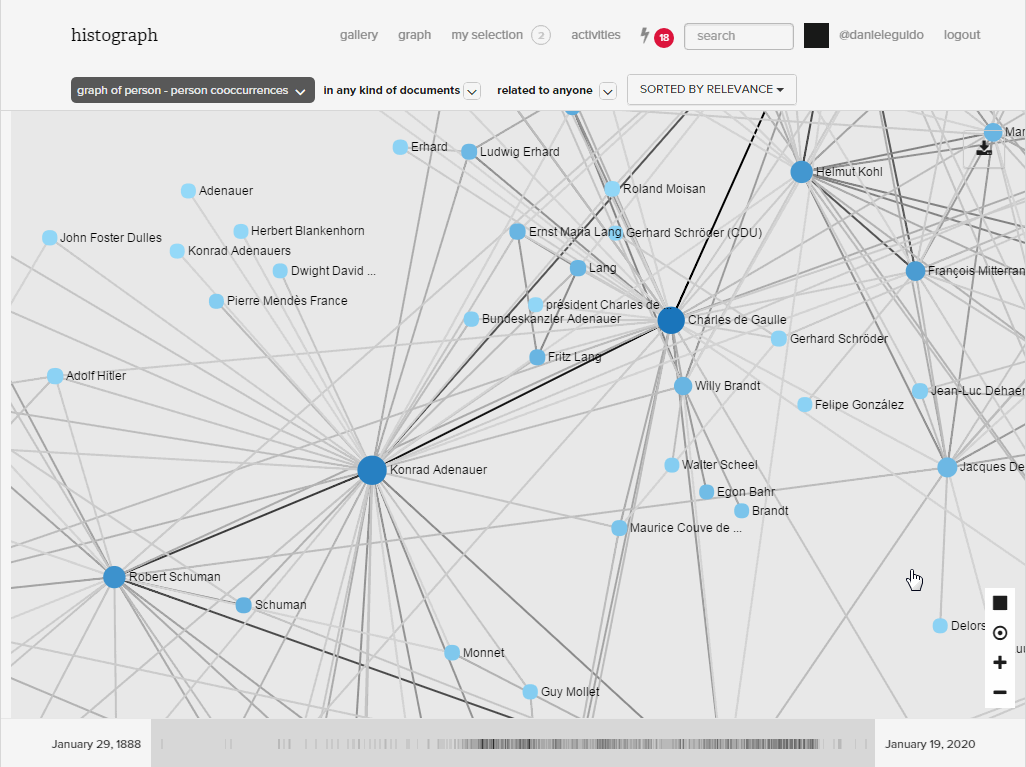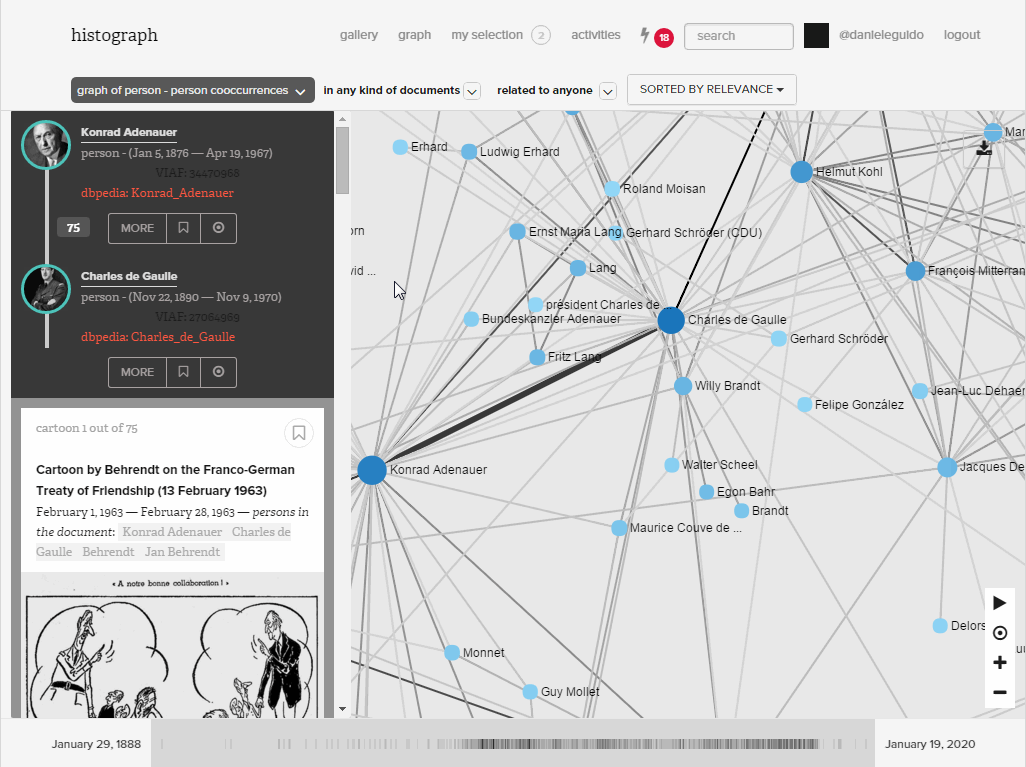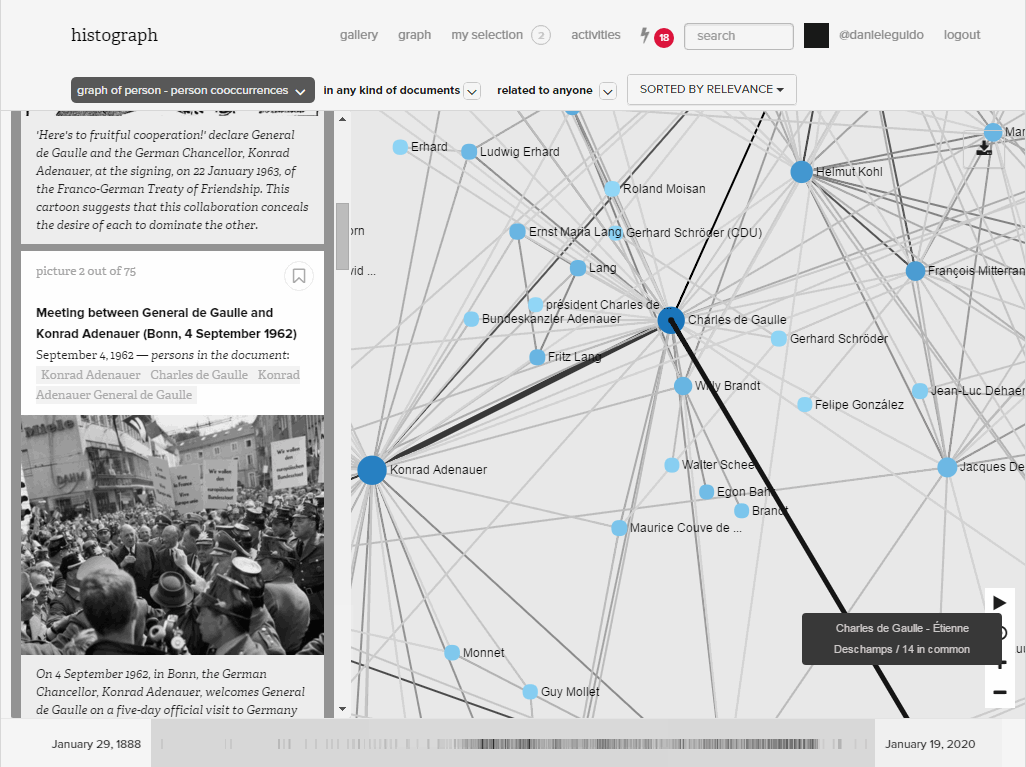
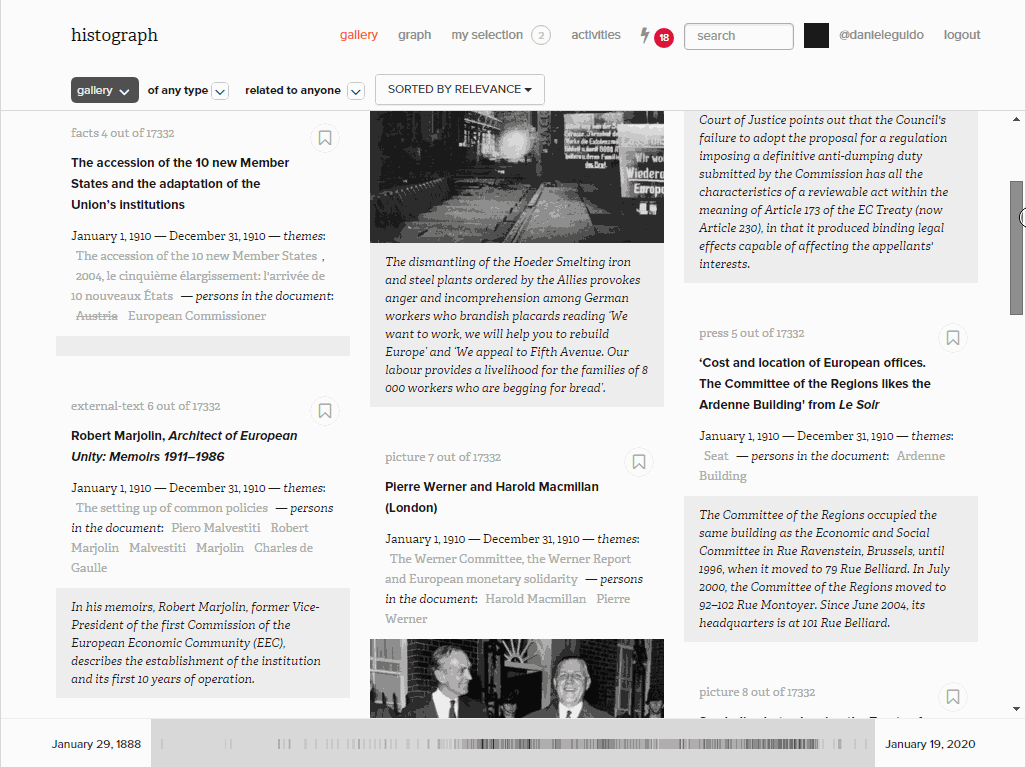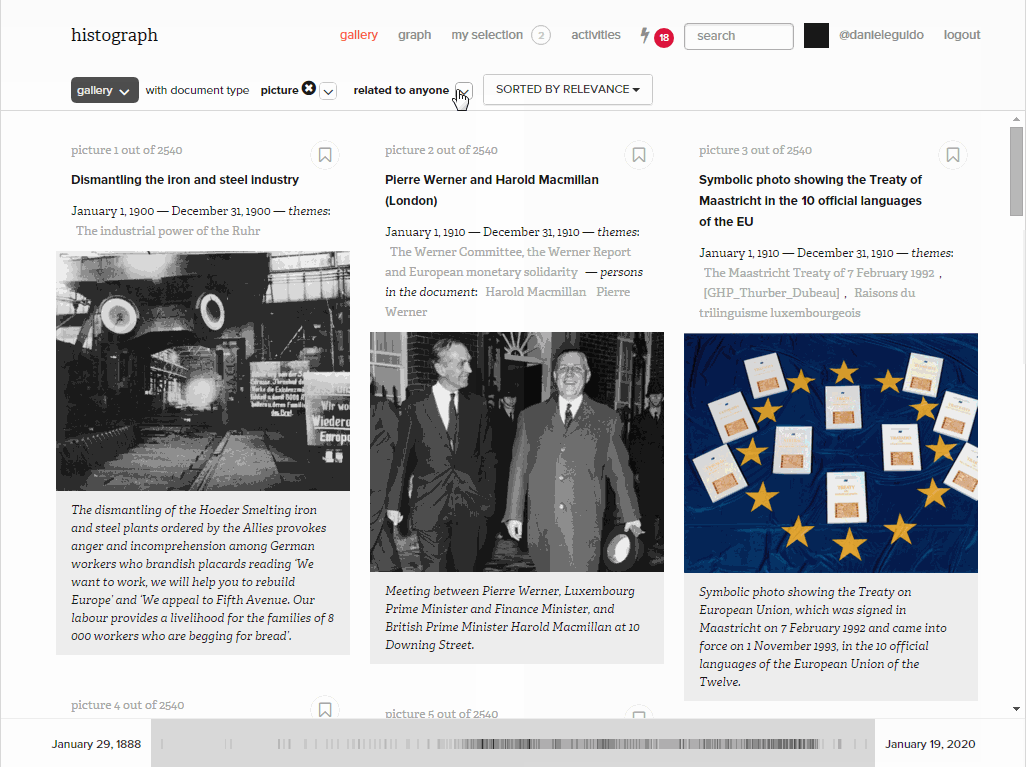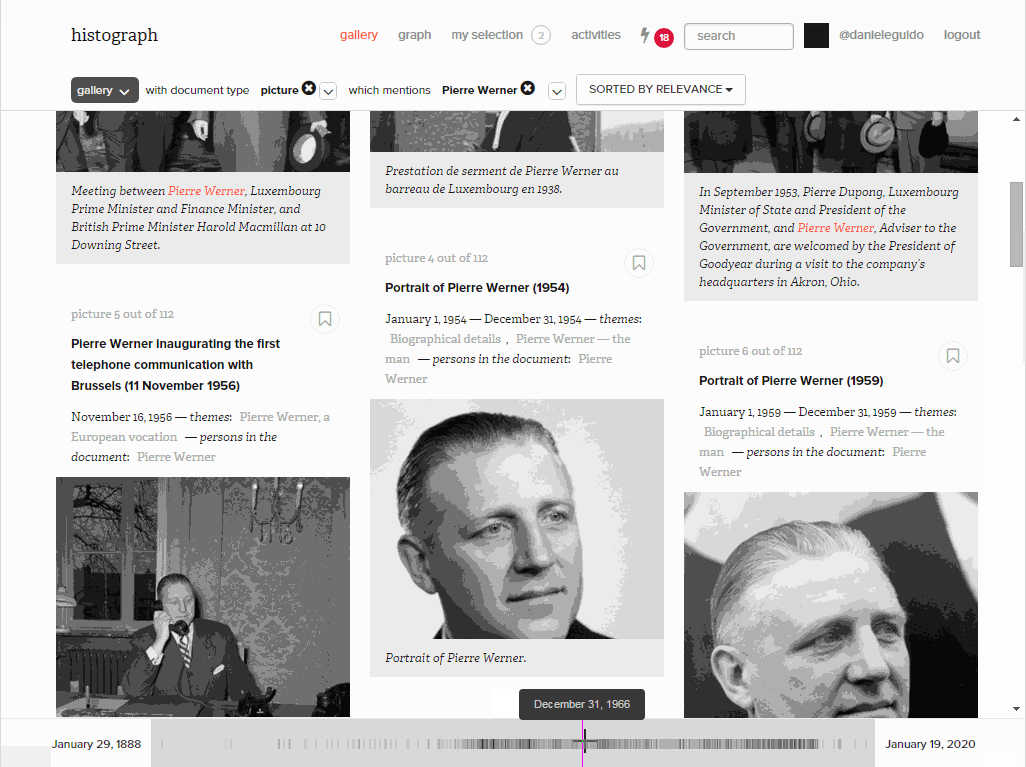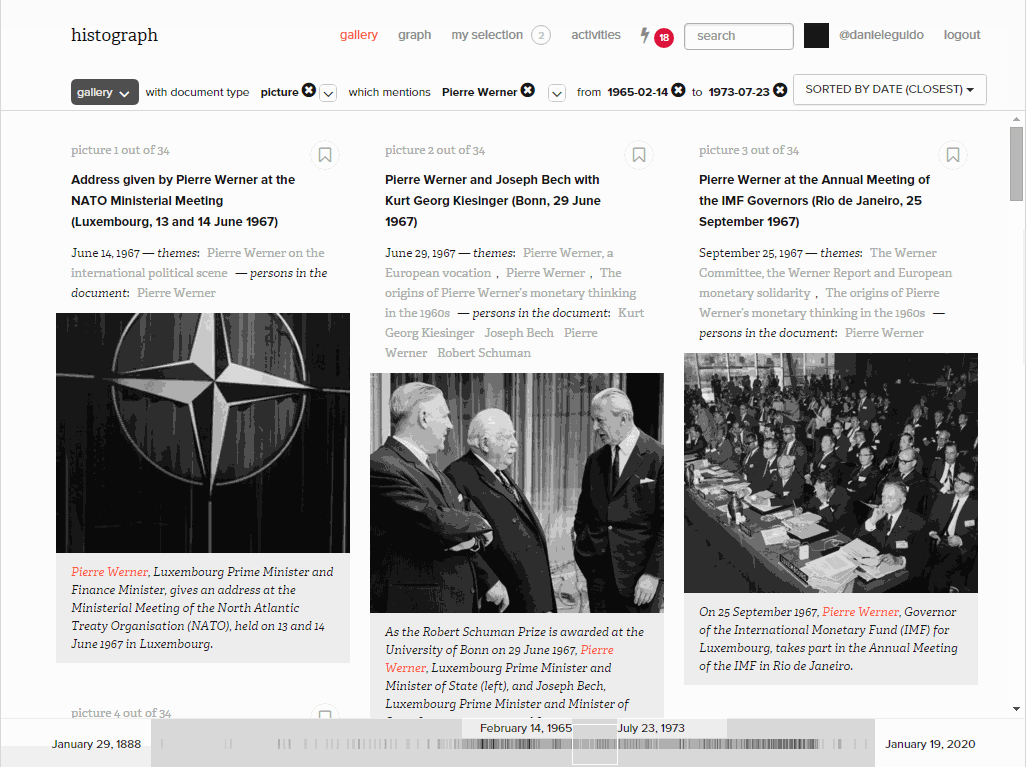
HistoGraph treats multimedia collections as networks. The underlying assumption is simple: if two people are mentioned together in a document, we assume that they may have something to do with each other. Whether or not such a relationship is interesting is in the eye of the beholder. Co-occurrence networks become huge and unwieldy very quickly, which forces us to filter them based on another simple assumption: the more often entities co-occur, the more likely it is that they have a meaningful relationship with each other. We combine these two assumptions with mathematical models (co-occurrence frequencies weighted by tf-idf specificity and Jaccard distances) which allow us to rank the list of co-occurrences. This tells us who appears with whom and in which documents.
Filters by entity, date range and document type
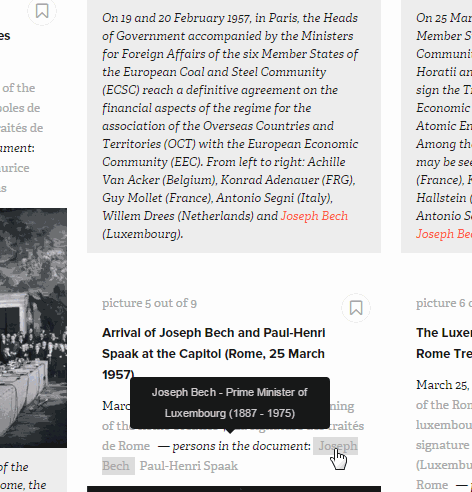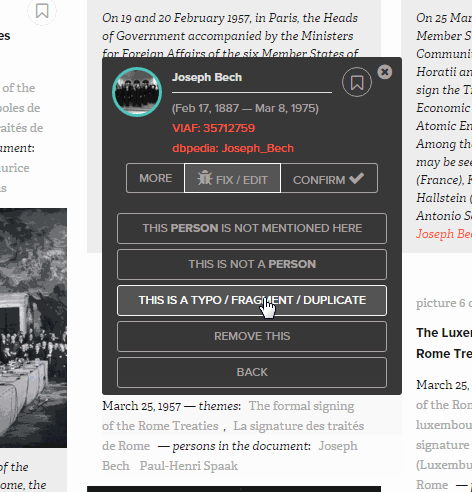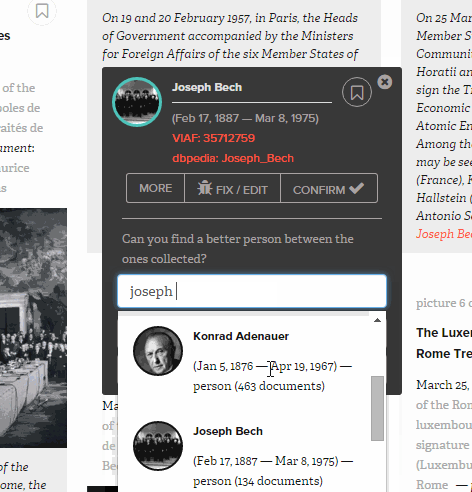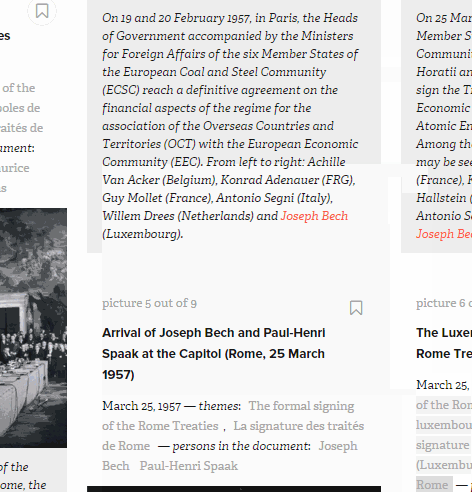
For those who already have an idea of what they are looking for, filters help to narrow down the number of documents by document type and entity. Here we looked for photos from a given date range in which Pierre Werner appears.
Ego networks provide a bird’s-eye-perspective on these relationships. They reveal the structure of the co-occurrence network, namely the relationships between all those who appear together with a given person. Clicking on an edge generates a list of documents in which both people appear. On this basis the user can decide whether or not this relationship is indeed of interest.
A timeline provides an additional filter on documents and shows how networks change over time.
Reveal relations between people
What connects a group of people? HistoGraph reveals a list and an interactive graph which retrieves all documents featuring a group of people and reveals co-occurrences among them.
Keep track of relevant documents
Users can keep track of documents they find useful by adding them to their favourites. HistoGraph displays this list of favourite documents both as a list and as a graph which reveals the relationships among them.